传统数仓的组织架构是针对离线数据的OLAP(联机事务分析)需求设计的,常用的导入数据方式为采用sqoop或spark定时作业逐批将业务库数据导入数仓。随着数据分析对实时性要求的不断提高,按小时、甚至分钟级的数据同步越来越普遍。由此展开了基于spark/flink流处理机制的(准)实时同步系统的开发。
Hudi通过映射Hoodie键(记录键+ 分区路径)到文件id,提供了高效的upsert操作。当第一个版本的记录写入文件时,这个记录键值和文件的映射关系就不会发生任何改变。换言之,映射的文件组始终包含一组记录的所有版本。
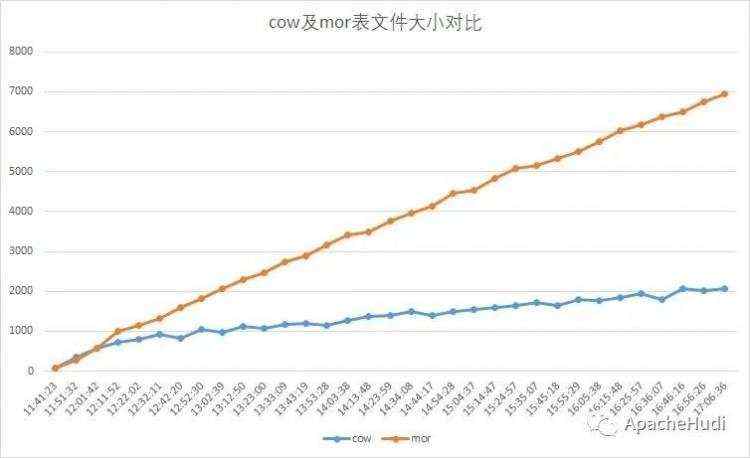
Merge On Read:采用列式存储文件(parquet)+行式存储文件(avro)存储数据。更新数据时,新数据被写入delta文件并随后以异步或同步的方式合并成新版本的列式存储文件。
以下是整合spark结构化流+hudi的示意代码,由于Hudi OutputFormat目前只支持在spark rdd对象中调用,因此写入HDFS操作采用了spark structured streaming的forEachBatch算子。具体说明见注释。
package pers.machi.sparkhudi
import org.apache.log4j.Logger
import org.apache.spark.sql.catalyst.encoders.RowEncoder
import org.apache.spark.sql.{DataFrame, Row, SaveMode}
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types.{LongType, StringType, StructField, StructType}
object SparkHudi {
val logger = Logger.getLogger(SparkHudi.getClass)
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.appName("SparkHudi")
//.master("local[*]")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("spark.default.parallelism", 9)
.config("spark.sql.shuffle.partitions", 9)
.enableHiveSupport()
.getOrCreate()
// 添加监听器,每一批次处理完成,将该批次的相关信息,如起始offset,抓取记录数量,处理时间打印到控制台
spark.streams.addListener(new StreamingQueryListener() {
override def onQueryStarted(queryStarted: QueryStartedEvent): Unit = {
println("Query started: " + queryStarted.id)
}
override def onQueryTerminated(queryTerminated: QueryTerminatedEvent): Unit = {
println("Query terminated: " + queryTerminated.id)
}
override def onQueryProgress(queryProgress: QueryProgressEvent): Unit = {
println("Query made progress: " + queryProgress.progress)
}
})
// 定义kafka流
val dataStreamReader = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "testTopic")
.option("startingOffsets", "latest")
.option("maxOffsetsPerTrigger", 100000)
.option("failOnDataLoss", false)
// 加载流数据,这里因为只是测试使用,直接读取kafka消息而不做其他处理,是spark结构化流会自动生成每一套消息对应的kafka元数据,如消息所在主题,分区,消息对应offset等。
val df = dataStreamReader.load()
.selectExpr(
"topic as kafka_topic"
"CAST(partition AS STRING) kafka_partition",
"cast(timestamp as String) kafka_timestamp",
"CAST(offset AS STRING) kafka_offset",
"CAST(key AS STRING) kafka_key",
"CAST(value AS STRING) kafka_value",
"current_timestamp() current_time",
)
.selectExpr(
"kafka_topic"
"concat(kafka_partition,'-',kafka_offset) kafka_partition_offset",
"kafka_offset",
"kafka_timestamp",
"kafka_key",
"kafka_value",
"substr(current_time,1,10) partition_date")
// 创建并启动query
val query = df
.writeStream
.queryName("demo").
.foreachBatch { (batchDF: DataFrame, _: Long) => {
batchDF.persist()
println(LocalDateTime.now() + "start writing cow table")
batchDF.write.format("org.apache.hudi")
.option(TABLE_TYPE_OPT_KEY, "COPY_ON_WRITE")
.option(PRECOMBINE_FIELD_OPT_KEY, "kafka_timestamp")
// 以kafka分区和偏移量作为组合主键
.option(RECORDKEY_FIELD_OPT_KEY, "kafka_partition_offset")
// 以当前日期作为分区
.option(PARTITIONPATH_FIELD_OPT_KEY, "partition_date")
.option(TABLE_NAME, "copy_on_write_table")
.option(HIVE_STYLE_PARTITIONING_OPT_KEY, true)
.mode(SaveMode.Append)
.save("/tmp/sparkHudi/COPY_ON_WRITE")
println(LocalDateTime.now() + "start writing mor table")
batchDF.write.format("org.apache.hudi")
.option(TABLE_TYPE_OPT_KEY, "MERGE_ON_READ")
.option(TABLE_TYPE_OPT_KEY, "COPY_ON_WRITE")
.option(PRECOMBINE_FIELD_OPT_KEY, "kafka_timestamp")
.option(RECORDKEY_FIELD_OPT_KEY, "kafka_partition_offset")
.option(PARTITIONPATH_FIELD_OPT_KEY, "partition_date")
.option(TABLE_NAME, "merge_on_read_table")
.option(HIVE_STYLE_PARTITIONING_OPT_KEY, true)
.mode(SaveMode.Append)
.save("/tmp/sparkHudi/MERGE_ON_READ")
println(LocalDateTime.now() + "finish")
batchDF.unpersist()
}
}
.option("checkpointLocation", "/tmp/sparkHudi/checkpoint/")
.start()
query.awaitTermination()
}
}













 京公网安备 11010802041100号
京公网安备 11010802041100号